



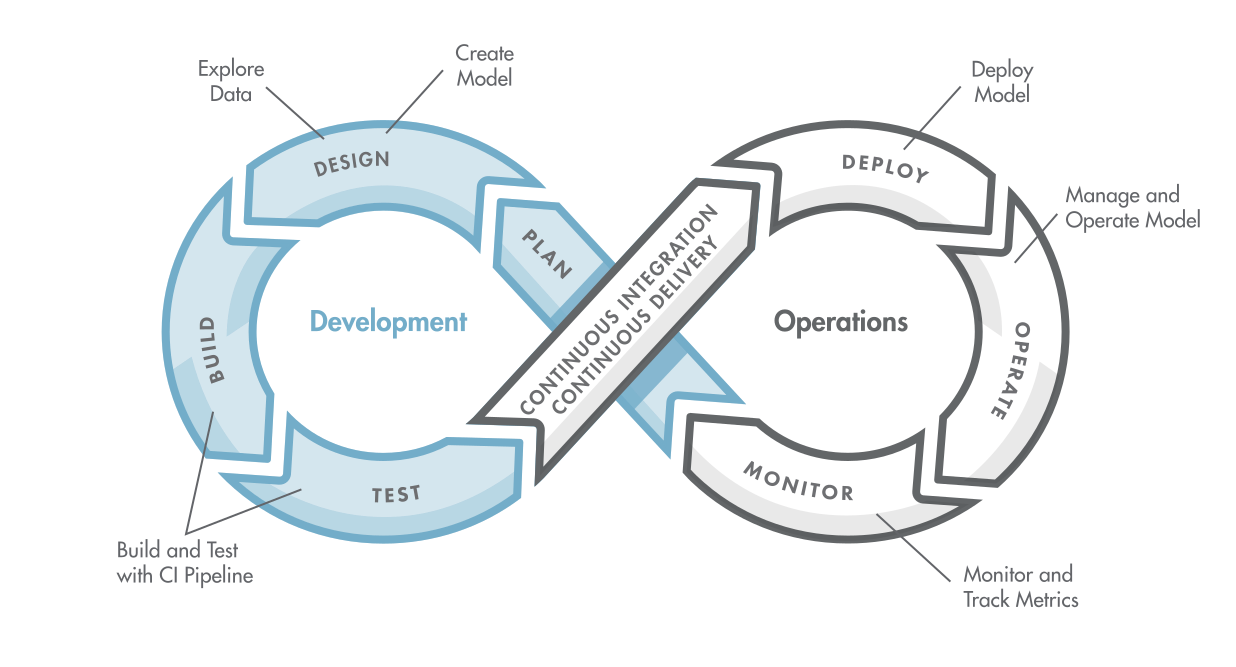
MLOps Lifecycle: From Data Collection to Model Monitoring

In the world of machine learning (ML), building and deploying models is only the beginning. To ensure that your models remain accurate, reliable, and relevant over time, it’s crucial to adopt a comprehensive MLOps (Machine Learning Operations) approach. The MLOps lifecycle encompasses a series of stages that govern the entire process, from data collection to model monitoring and retraining.
1. Data Collection
Data is the backbone of any machine learning project. The quality and quantity of data significantly impact the performance of the ML model. The data collection phase involves gathering relevant data from various sources, which could include databases, APIs, web scraping, and more.
Key Activities:
Data Acquisition: Collecting raw data from diverse sources.
Data Ingestion: Loading data into a storage system where it can be accessed and processed.
Data Annotation: Labeling data for supervised learning tasks.
Best Practices:
Ensure Data Quality: Validate data for accuracy, completeness, and consistency.
Automate Data Collection: Use pipelines to automate data ingestion and minimize manual errors.
Comply with Privacy Regulations: Ensure that data collection complies with legal standards, such as GDPR.
2. Data Processing
Once data is collected, it must be cleaned and processed to be useful for training models. Data processing involves transforming raw data into a format suitable for analysis.
Key Activities:
Data Cleaning: Removing duplicates, handling missing values, and correcting errors.
Data Transformation: Normalizing, scaling, and encoding data.
Feature Engineering: Creating new features that can improve model performance.
Best Practices:
Automate Data Cleaning: Implement scripts to handle routine data cleaning tasks.
Maintain Data Lineage: Track data transformations to ensure reproducibility.
Use Scalable Processing: Utilize distributed processing frameworks like Apache Spark for large datasets.

3. Model Training
In this phase, data scientists use the processed data to train machine learning models. This involves selecting the appropriate algorithms, tuning hyperparameters, and evaluating model performance.
Key Activities:
Model Selection: Choosing the right algorithm based on the problem type and data characteristics.
Hyperparameter Tuning: Optimizing hyperparameters to improve model performance.
Model Evaluation: Using metrics like accuracy, precision, recall, and F1-score to assess model performance.
Best Practices:
Version Control for Models: Track different versions of models and their parameters.
Use Automated ML: Leverage AutoML tools to streamline model selection and hyperparameter tuning.
Cross-Validation: Employ techniques like k-fold cross-validation to ensure robust model evaluation.
4. Model Deployment
After a model is trained and evaluated, it needs to be deployed to a production environment where it can make predictions on new data. Deployment ensures that the model is accessible to end-users or other systems.
Key Activities:
Model Packaging: Wrapping the model in a format that can be easily deployed.
API Development: Creating APIs to serve model predictions.
Containerization: Using Docker or Kubernetes to manage model deployment at scale.
Best Practices:
Continuous Integration/Continuous Deployment (CI/CD): Automate the deployment process to ensure consistent and reliable updates.
Monitor for Drift: Implement mechanisms to detect data or concept drift that may degrade model performance over time.
Ensure Security: Secure APIs and data to prevent unauthorized access and attacks.
5. Model Monitoring
Model monitoring is critical to ensure that deployed models continue to perform well in a production environment. This phase involves tracking model performance and detecting issues like data drift, model drift, and anomalies.
Key Activities:
Performance Monitoring: Continuously measure model performance using relevant metrics.
Data Drift Detection: Identify changes in input data distribution that may affect model predictions.
Alerting and Logging: Set up alerts for performance degradation and log events for debugging.
Best Practices:
Real-time Monitoring: Implement real-time monitoring to catch issues as they occur.
Feedback Loops: Create feedback loops to retrain models with new data.
Scalable Monitoring: Use scalable tools like Prometheus and Grafana for large-scale monitoring.
6. Feedback & Iteration:
Insights from monitoring feed back into the initial stages. If the model’s performance deteriorates, data scientists can retrain the model with fresh data or explore new algorithms. This continuous feedback loop ensures the model stays relevant and delivers optimal results.
The MLOps Advantage:
By establishing a structured MLOps lifecycle, organizations enjoy several benefits:
Faster Time-to-Value: Automating processes and streamlining model deployment lead to quicker delivery of ML solutions.
Improved Model Performance: Continuous monitoring and feedback loops ensure models stay accurate and effective.
Enhanced Collaboration: MLOps fosters collaboration between data scientists, engineers, and operations teams.
Scalability & Governance: MLOps practices enable robust model management and facilitate scaling ML deployments.
Conclusion
MLOps is an essential practice for modern machine learning projects, ensuring that models are not only developed with high accuracy but also deployed and maintained effectively in production environments. By following the MLOps lifecycle from data collection to model monitoring, organizations can achieve reliable, scalable, and efficient ML systems that drive business value. Embracing MLOps best practices will help data scientists and engineers work more collaboratively, streamline workflows, and ultimately deliver more robust and impactful ML solutions.