



How to Build Data Pipelines for ML Projects

In this article , I will cover an introduction to the field of data engineering with a practical application on how to build a data pipeline
What is Data Engineering

Data engineering is a field within data science focused on designing, building, and maintaining the systems and infrastructure that collect, store, and process large volumes of data.
The point of data engineering is to make the data available for analytics and any ML application
So what does a data engineer do ?
Data Collection: Gathering data from various sources, such as databases, APIs, log files, and external datasets.
Data Storage: Ensuring data is stored efficiently and securely in databases, data warehouses, or data lakes if you have a very amount large of data.
Data Processing: Transforming raw data into a clean, structured format suitable for analysis. (This often involves data cleaning, normalization, and aggregation )
Data Integration: Combining data from different sources to provide a unified view of the data (For pharmaceutical industry, if you want to launch a product, this can include; marketing companies, reps promotions, sales promotions and so on to have an idea about the performance of the launch)
Data Pipeline Development: Creating automated workflows (ETL — Extract, Transform, Load) that move data from source to destination while ensuring data quality and consistency.
Performance Optimization: Ensuring data processing systems are optimized for speed and efficiency, minimizing latency and maximizing throughput.
Data Security: Implementing measures to protect data from unauthorized access and breaches.
What is a data pipeline
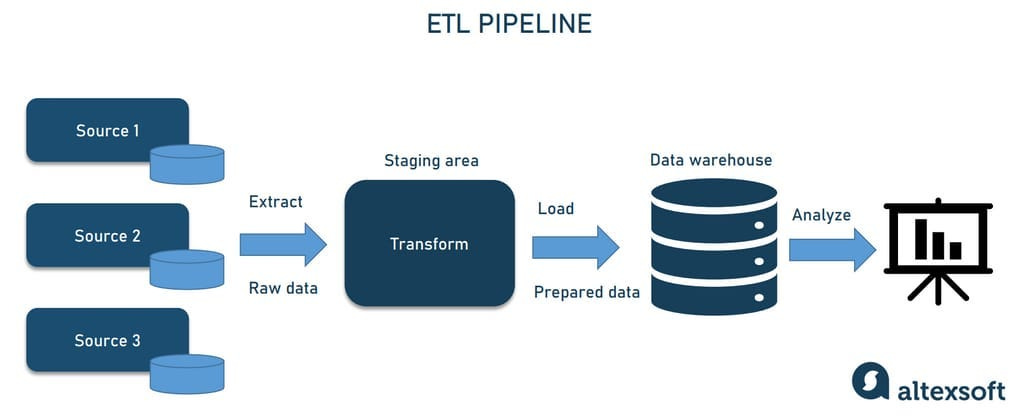
Basically, a data pipeline is a series of processes that move data from one place (point A) to another (point B), typically involving various steps such as extraction, transformation, and loading of data.
The simplest data pipeline involves extracting data from point A and directly loading it to point B. However, there is an additional step for many machine learning applications, between extraction and loading called “transformation”.

The transformation step involves the process of converting raw data into a more suitable format or structure for analysis or further processing.
It also involves other data preprocessing tasks such as changing data types, handling special characters, removing duplicates, feature engineering, encoding, normalization and scaling, managing null values, and general data cleaning.
Pipeline Paradigms

1 — ETL (Extract, Transform, Load):
Extract: Data is pulled from the source.
Transform: Data is transformed into the required format.
Load: Data is loaded into a database or data warehouse.
ETL pipeline works best where the data is represented in rows and columns, so it’s serve a narrow set of use cases
2 — ELT (Extract, Load, Transform):
Extract: Data is pulled from the source.
Load: Data is loaded into the destination with minimal adjustments, before the transformation! for more flexibility of use.
Transform: Data is transformed on a case-by-case basis as needed.
This pipeline compared to ETL, supports all data formats and, because the data is transformed on a case-by-case basis, it offers flexibility and accommodates a wide range of use cases.
Data Pipeline Steps
1 — Extract : Most data sources today are managed by third parties, requiring access through APIs.
Additionally, custom extraction methods may be needed, such as legally scraping public web pages, extracting data from documents in file systems, or gathering sensor data.
2 — Transform : When extracting data from raw sources, it is often semi-structured or unstructured and needs to be converted into a structured format.
Semi-structured : includes text in JSON format or CSV files. JSON is particularly popular because API responses are typically in JSON format.
Unstructured data : includes documents, PDFs, and images.
As I said before, common tasks in this process include:
Managing data types and ranges of specific variables
Deduplication
Imputing missing values
Handling special characters and values
Feature engineering
3 — Load : Once the data is processed, it is loaded to be available for machine learning training or inference.
The simplest way to load the data is to save it in the same directory as your machine learning project, which is suitable if the data is from a single source, is MB-scale, and serves one use case.
The second option is to use a cloud storage solution. However, as your data and use cases start to scale, this simple cloud storage solution may become inadequate.
The third option is to use a database like MySQL or PostgreSQL or big cloud storage solution. As your data and use cases continue to grow, transitioning to a data warehouse becomes necessary, providing a more modern and scalable solution.
Note:
The main difference between data warehouses and databases is that data warehouses have a distributed infrastructure, allowing them to scale effectively.
If you have an overwhelming amount of data to manage and essentially endless use cases, you may want to consider a data lake, which utilizes a more modern ELT (Extract, Load, Transform) pipeline as described.
Orchestration

Once all the steps of the data pipeline are defined, everything needs to be brought together. While a simple ETL process can be handled with a few lines of Python, as the scale increases, the need for orchestration tools becomes more pronounced.
The primary concept behind orchestration is to visualize your data pipeline as a Directed Acyclic Graph (DAG). This means tasks are represented as nodes, and dependencies between tasks are represented by arrows.
A typical orchestration scenario might involve a trigger, such as starting the data extraction process every day at midnight. The data is then transformed and loaded into its destination.
Some of the tools available for orchestration include :
Airflow.
Dagster.
Perfect.
Argo.
Mage.
Another critical aspect of orchestrating this data pipeline is observability, which provides visibility into the process of your pipeline. (Observability functions are often integrated into the orchestration tools mentioned above)

To understand how it’s work, I found a good example from this Github repo, It demonstrates using the YouTube API to extract text from videos, which is then transformed and loaded for machine learning purposes. let’s get started.
I — Extraction
1 — Install the necessary libraries
import requests
import json
import polars as pl
from API import youtube #My Youtube API key
from youtube_transcript_api import YouTubeTranscriptApiNote: An API file is a .py file that contains solely my YouTube API key. Here's an example of what it typically contains.
youtube = 'my key is here'2 — Define a function to extract the data : This function retrieves specific details (video_id, datetime, and title) from YouTube videos while filtering out non-video content. It returns a list of dictionaries, each containing the video ID, publication date, and title.
def getVideoRecords(response: requests.models.Response) -> list:
video_record_list = []
for raw_item in json.loads(response.text)['items']:
# only execute for youtube videos
if raw_item['id']['kind'] != "youtube#video":
continue
video_record = {}
video_record['video_id'] = raw_item['id']['videoId']
video_record['datetime'] = raw_item['snippet']['publishedAt']
video_record['title'] = raw_item['snippet']['title']
video_record_list.append(video_record)
return video_record_list3 — Defining the channel ID and starting the extraction : For that example, I’ll use the channel ID of a channel I enjoy, ‘Grubby,’ known as one of the best Warcraft players in the world !
Grubby
I love gaming the most when it is a shared experience with others. Coming together for an appreciation of gaming…
You can use any channel. To find the channel ID, you can use the following link: https://commentpicker.com/youtube-channel-id.php
3.1 — So, we start by creating an instance for the channel ID and defining the endpoint for the YouTube search API, as we will be searching on the platform.
channel_id = "UCCF6pCTGMKdo9r_kFQS-H3Q"
url = "https://www.googleapis.com/youtube/v3/search"3.2 — Next, we need to initialize some variables that we will be using.
page_token = None
video_record_list = []page_token is initialized to None. It will be used to navigate through multiple pages of search results.
video_record_list is an empty list to store the extracted video records.
3.3 — Starting the extraction : We will have a while loop that will continue to run as page_token is not 0 (until there are no more pages of results).
Inside the loop, we will set up the parameters for the API call, make the request using the YouTube search API, and append the video records to a list using the function we defined earlier to store the extracted data in a list of dictionaries.
We also will extract the nextPageToken from the response to get the next page of results. If there is no nextPageToken (indicating that there are no more pages), we will set page_token to 0 to terminate the loop.
# extract video data across multiple search result pages
while page_token != 0:
# define parameters for API call
params = {"key": youtube, 'channelId': channel_id, 'part': ["snippet","id"],
'order': "date", 'maxResults':50, 'pageToken': page_token}
# make get request
response = requests.get(url, params=params)
# append video records to list
video_record_list += getVideoRecords(response)
try:
# grab next page token
page_token = json.loads(response.text)['nextPageToken']
except:
# if no next page token kill while loop
page_token = 04 — Transform the results into a DataFrame
df = pl.DataFrame(video_record_list)
df.head()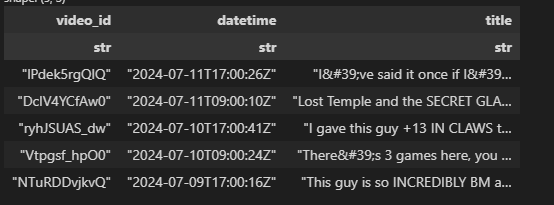
5 — Create a function to extract text from a transcript dictionary
def extract_text(transcript: list) -> str:
text_list = [transcript[i]['text'] for i in range(len(transcript))]
return ' '.join(text_list)6 — Initiating Extraction (May Take Time): Now we will begin transcribing each video_id present in the DataFrame. If there is no text available, we will label it as ‘n/a’. The results will be stored in a column named ‘transcript’ within the DataFrame.”
transcript_text_list = []
for i in range(len(df)):
# try to extract captions
try:
transcript = YouTubeTranscriptApi.get_transcript(df['video_id'][i])
transcript_text = extract_text(transcript)
# if not available set as n/a
except:
transcript_text = "n/a"
transcript_text_list.append(transcript_text)
df = df.with_columns(pl.Series(name="transcript", values=transcript_text_list))
df.head()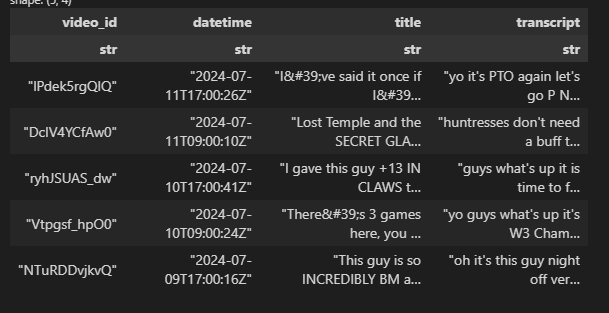
II — Transform
1 — Duplicates: There were duplicates in the gathered data, as the shape of the data did not match the number of unique rows in the DataFrame.
# Check for duplicate values
print("shape:", df.shape)
print("n unique rows:", df.n_unique())
for j in range(df.shape[1]):
print("n unique elements (" + df.columns[j] + "):", df[:,j].n_unique())We need to detect these duplicates and remove them from the DataFrame.
sorted_df = df.sort('video_id')
# Identify duplicates based on 'video_id'
duplicates_mask = (sorted_df['video_id'].shift(1) == sorted_df['video_id'])
# Print information about duplicates
print("Duplicate rows:")
print(sorted_df.filter(duplicates_mask))
# Remove duplicates and update df
df = sorted_df.filter(~duplicates_mask)
# Print updated shape and unique counts
print("Shape after removing duplicates:", df.shape)
print("Number of unique rows:", len(df))
for col in df.columns:
print(f"Number of unique elements ({col}):", df[col].n_unique())2 — Data type adjustment: We need to change the ‘datetime’ column in the DataFrame from string to datetime format.
df = df.with_columns(pl.col('datetime').cast(pl.Datetime))
print(df.head())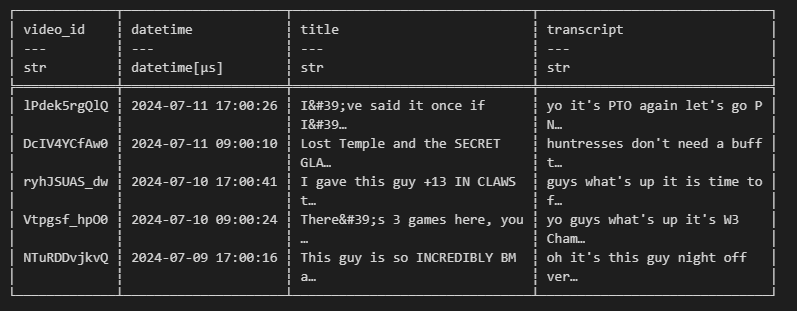
3 — Handling special characters: In this section, we can use Regex to address this issue. As seen in the DataFrame, there are special characters such as I', '….
print(df['title'][3])
# There's 3 games here, you need to see all 3 to appreciate the 3rd - WC3special_strings = [''', '&', 'I'']
special_string_replacements = ["'", "&", "'"]
for i in range(len(special_strings)):
df = df.with_columns(df['title'].str.replace(special_strings[i], special_string_replacements[i]).alias('title'))
df = df.with_columns(df['transcript'].str.replace(special_strings[i], special_string_replacements[i]).alias('transcript'))print(df['title'][3])
# There's 3 games here, you need to see all 3 to appreciate the 3rd - WC3
df
III — Load
Now, we can save our DataFrame in the desired format for future use or retrieval.
df.write_parquet('video-transcripts.parquet')
df.write_csv('video-transcripts.csv')